JLG蓄电池关于电池健康状况猜测,所提出的模型整合了四种先进深度学习办法的优势
关于电池健康状况猜测,所提出的模型整合了四种先进深度学习办法的优势:卷积神经网络(CNN)、广义回归神经网络(WNN)、权重门控双向长短期回想网络(WBILSTM)和注意力机制(AM)。这种混合办法运用了CNN的特征提取才华、WNN的多分辨率剖析、WBILSTM的时刻办法学习和AM对要害信息的重视,以行进锂离子电池健康状况估计的精度和可靠性。
3.1. 运用模糊C均值技术对具有类似特性的电池进行聚类
FCM算法是一种流行的模糊聚类办法,由Dunn在1973年初度提出[18],并由Bezdek在1980年进一步打开[19]。该办法依据数据点到聚类中心的间隔为其分配从属度,这些中心点在聚类进程中迭代优化[20]。
设 \( X = [x_1, \ldots, x_n] \) 标明一组 \( n \) 个数据点,需求将其划分为 \( c \) 个簇。模糊C均值算法的中心方针是最小化以下方针函数:
(2)在这个公式中, \( m \) 是模糊参数,它操控着簇之间的重叠程度,\( v_k \) 标明第 \( k \) 个簇的中心点,\( u_{ik} \) 标明第 \( i \) 个数据点归于第 \( k \) 个簇的从属度,受预界说束缚的束缚。
FCM算法迭代工作,在更新从属矩阵 \( U = [u_{ik}] \) 和中心点矩阵 \( V = [v_k] \) 之间替换进行,直到收敛间断。当满足以下间断准则时,该进程间断:
(3)这儿,ϵ 是一个小的正阈值,t 标明当时迭代次数,当各次迭代之间的从属度改动低于ϵ时,就达到了收敛。值得注意的是,当模糊参数 m 设置为 1 时,FCM 算法就简化为传统的 k-均值聚类办法。
为了确保核算功率和聚类精度,FCM算法的间断条件被精心选择。收敛的阈值是依据经历测验供认的,在测验中它一向可以在最小化核算时刻和结束安稳的聚类分配之间获得平衡。具体来说,当相邻两次迭代的方针函数改动低于预定的阈值时,算法间断,确保进一步的迭代不会明显改动聚类中心点。这种办法确保了算法收敛到可靠的解,一起避免了不必要的核算开支。
FCM聚类算法是一种有用的东西,可用于分组具有类似功用特性的电池。经过运用模糊办法,该技术容许电池以不同的从属度归于多个簇,然后结束更详尽的分类。这关于辨认具有类似退化办法、充放电循环和整体健康状况的电池特别有用,尽管单个电池之间存在固有的差异。FCM算法经过供给依据操作行为的数据驱动办法来对电池进行分类,然后行进了电池处理系统(BMS)的准确性,这关于优化维护和猜测未来功用至关重要,这也将在本研讨中得到展示。
在本研讨中,电池电压和温度的最小值、最大值、平均值及标准差被用作FCM分类的输入。这些计算方针之所以被选中,是因为它们可以全面捕捉电池功用随时刻改动的变异性和趋势。FCM算法处理这些输入以生成聚类索引,然后将其输入到FCM-CNN-WNN-WBILSTM-AM模型中。这种混合办法运用了FCM聚类和CNN-WNN-WBILSTM-AM深度学习才华的优势,以行进电池功用猜测和分类的准确性。聚类索引作为一个要害特征,包含了电池数据中的潜在办法,使得FCM-CNN-WNN-WBILSTM-AM模型可以做出更明智、更准确的电池健康和功用猜测。
3.1 卷积层和池化层
精心规划的卷积层和池化层关于完全的数据预处理至关重要,它们能有用地从输入数据中去除噪声,一起提取后续网络层所需的要害特征。图2展示了CNN的结构。卷积层运用内核对输入数据进行卷积操作,生成特征值,这些输入数据以矩阵办法结构化。这与CNN的首要方针——提取序列特征是一起的。卷积核作为一个具有预界说系数的细小窗口,在输入数据上滑动,遇到每个图像块时进行卷积,并发生一个代表特定特征的矩阵。经过在输入数据上运用多个卷积核,模型生成的增强特征优于原始输入特征,然后行进了模型的整体功用。为了引进非线性,卷积层一般后面会跟着激活函数。然后,池化层下降特征图的维度,创立出包含卷积特征的矩阵,然后行进系统的鲁棒性。CNN和WBILSTM网络的协同效果结合了它们在空间特征提取和时刻依托建模方面的优势,供给了一种强健的办法,适用于各种数据类型和运用场景,从捕捉序列办法到剖析时刻序列数据[21]。
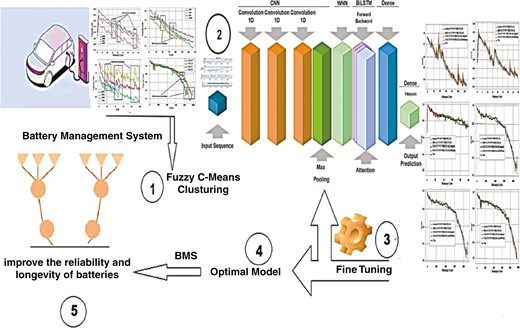
图1.
电动汽车中锂离子电池SOH的预算流程图。
3.2 小波神经网络
WNN是一个鲁棒的模型,可以动态生成依据小波的参数[22]。与传统的神经网络(如BP-NN)不同,WNN用一系列由Morlet小波生成函数导出的小波函数替代了标准激活函数[22]。图3展示了WNN的结构,它由三个层组成:一个具有k个节点的输入层,一个具有L个节点的躲藏层,以及一个具有k个节点的输出层。
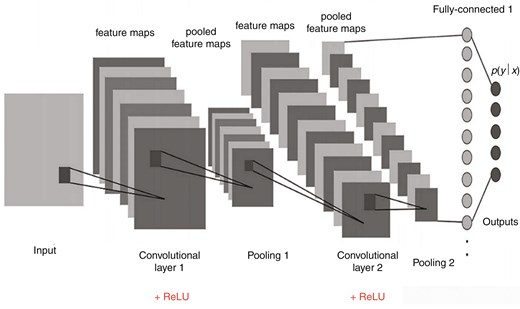
图2.
卷积神经网络的架构。
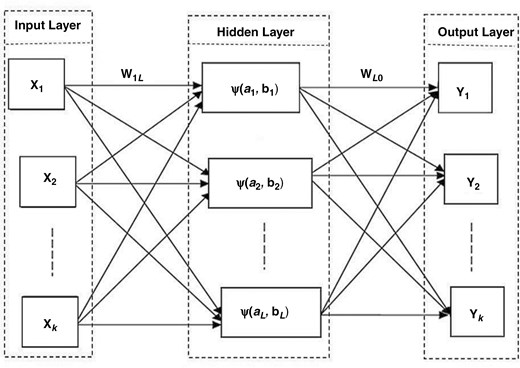
图3.
WNN的架构。
在练习阶段,躲藏层的参数——例如权重 \( w_{il} \) 和 \( w_{lo} \)、小波胀大参数 \( a \) 和小波平移参数 \( b \) ——被迭代优化。网络的输出 \( y_i \) 依据输入数据 \( x_i \) 核算得出。这种联络用数学公式标明为:
在公式(4)中,术语“净 l”标明网络第 l 层的净输入。它被核算为输入的加权和(wilxi),经过偏置项 bl 调整并由因子 al 缩放。然后,这个净输入经过激活函数生成该层的输出。“net”函数本质上是聚合输入信号,然后在每个神经元上运用激活函数 [22]。
作为激活函数的莫雷小波函数界说为:
3.3 长短时回想
RNN的一种先进变体是LSTM(长短期回想网络),由Hochreiter和Schmidhuber引进。LSTM模型专门规划用于学习长时刻依托联络,解决了序列处理中常见的梯度爆破和消失问题。这些增强型回想模型优于其他序列学习技术,使其特别适用于触及序列数据处理和猜测的使命。LSTM单元包含三个首要部分:输入门、遗忘门和输出门,它们有用地处理信息流并在长时刻内保存重要值。RNN-LSTM架构在每个时刻步处理两个输入:当时输入向量 (Xt) 和前一个时刻步的躲藏状况 (Ht−1)。经过逻辑运算和非线性变换生成输出,一般经过全联接层并运用激活函数如tanh、sigmoid、softmax或Adam。LSTM的成功归功于其专用组件,使其成为各种运用的强健东西。LSTM单元的结构如图4所示 [23]。
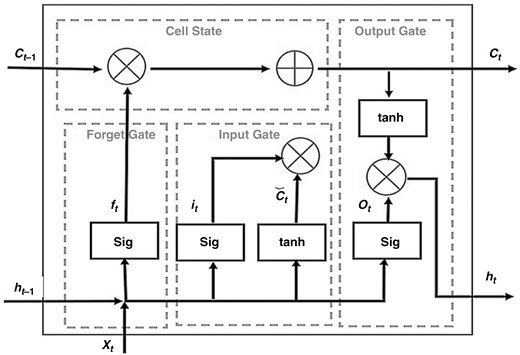
图4.
长短期回想单元。
-
• 单元状况操作:单元状况操作由以下方程描绘:
where:
-
遗忘门操作:遗忘门操作由以下方程描绘:
(9)
where:
-
输入门操作:输入门操作由以下方程描绘:
(10)
(11)
where:
-
输出门操作:输出门操作由以下方程描绘:
(13)
where:
在LSTM架构[24]中,所有门都具有相同的维度和方程结构,首要区别在于每个门相关的参数。这些门中的激活函数会批改特定规划内的元素值,例如[0,1]或[-1,1],这便是为什么它们被称为门。这些门操控LSTM网络中的信息流,选择在每个时刻步哪些信息被保存、丢掉或更新[13,23]。
输入门选择当时输入的新核算状况中有多少应该被容许传递到内部状况,然后有用地调度从当时输入到内部状况的信息流。另一方面,遗忘门操控应该保存和容许传递到内部状况的前一状况的多少,操控早年一状况到当时内部状况的信息流。两个门协同作业以处理网络的回想,使其可以跟着时刻的推移保存相关信息并丢掉无关数据。
输出门选择内部状况应向外部网络泄露多少信息,影响信息传递到下一时刻步长和网络中的更高层。它调度从内部状况到输出的信息流,确保只需相关部分的内部回想传递给后续的层或时刻步长,然后坚持模型处理序列数据的功率。
经过调整门控单元的激活值,LSTM模型可以有用地操控信息流,然后可以捕捉和运用来自当时和之前输入的相关信息。这种在每个时刻步长中选择性地保存、遗忘或传递信息的才华,使得模型可以有用学习长时刻依托联络,并在触及序列数据的使命中做出准确的猜测。
回想单元 \( C_t \) 是经过当时时刻步的候选回想单元与前一个时刻步的回想单元 \( C_{t-1} \) 运用逐元素乘法(由操作符 \( \circ \) 标明)生成的。遗忘门和输入门经过操控信息流来操控这个核算进程。遗忘门选择应该保存多少前一个回想 \( C_{t-1} \),而输入门选择应该将多少新的候选回想合并到当时回想 \( C_t \) 中,然后容许相关信息的传递。这种机制使得模型可以在长时刻内保存重要的信息,一起丢掉不必要的部分。
躲藏状况 \( h_t \) 由躲藏状况标明,其间输出门操控从回想单元到躲藏状况 \( h_t \) 的信息流。躲藏状况的值经过双曲正切激活函数束缚在规划 \([-1, 1]\) 内。值得注意的是,靠近 1 的输出门值容许回想单元的信息传递到躲藏状况,使其可以被输出层运用。相反,靠近零的输出门值标明来自回想单元的数据保存在内存中,不会传递到躲藏状况。
3.4. 双向长短期回想网络
如图5所示,双向长短期回想网络(BILSTM)是一种先进的神经网络架构,旨在对序列数据建模时表现超卓。其一起的才华可以从曩昔和未来的时刻步中捕获信息,使其特别适用于触及时刻依托性的使命。经过运用BILSTM,咱们可以有用地剖析和猜测杂乱的序列,这使得它在比如自然语言处理、时刻序列剖析等运用中具有极高的价值,在咱们的上下文中,它也适用于电动汽车中锂离子电池的SOH的准确猜测[21-24]。
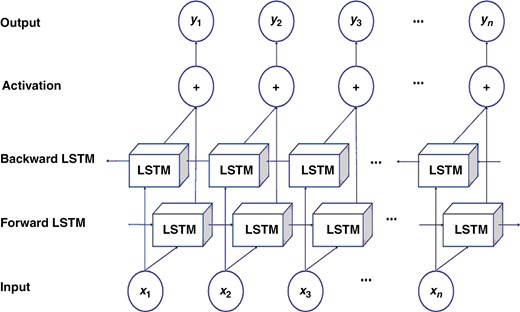
图5.
双向长短期回想模型的架构。
3.5 小波双向长短期回想
小波双向长短期回想循环神经网络(wavelet BILSTM RNN)是一种专门为处理序列数据而规划的杂乱架构。其要害优势在于可以从曩昔和未来的时刻步中捕获信息,使其在需求了解时刻依托性的使命中特别有用[15]。在这项研讨中,小波双向长短期回想网络运用莫雷小波函数作为BILSTM层的激活函数,使网络可以提取杂乱的时序特征。实值莫雷小波函数界说如下:
(14)这个方程结合了余弦波和正态包络,其间 \( h \) 标明时刻或空间变量。
3.6 注意力机制
在注意力-双向长短期回想模型中结束的神经网络中的AM,经过在练习进程中自适应地分配输入特征的重要性,模拟了人类大脑的视觉处理[14-18]。这使得模型可以自主学习输入数据的哪些部分最相关,类似于人类的注意力机制。这种办法已经在依据视频的人员检索和面部年纪估计等使命中证明了其成功性,行进了模型的功用和可解释性[25]。
处理AM的中心公式如下:
其间 \( u \) 和 \( w_A \) 是权重参数,\( b_A \) 是偏置,\( e_t \) 标明由时刻步 \( t \) 的 BILSTM 输出向量 \( h_t \) 供认的注意力概率分布值,\( s_t \) 是注意力层的输出。
首要经过调整不同通道的权重系数来表现。这些系数被更新和优化,以完善模型如何为每个通道的信息分配重要性[24, 25],毕竟在给定的核算环境中行进模型的练习功率。